
これまで「結合層」や「活性化層」といったニューラルネットワークの演算、誤差逆伝播法によるモデルの学習、データセットの扱い方について学びました。
本記事では集大成としてPytorchで簡単なモデルを作成して学習してみましょう。もし途中分からないかとがあったら、過去の記事を復習してチャレンジしてみてください。
データセットの準備
今回構築するモデルは画像データを入力して、その画像が「猫」である確率を出力します。学習に使用する画像データを自力で調達するのは困難なので、CIFAR-10データセットを使いましょう。CIFAR-10データセットの扱い方について分からなければ過去の記事をご覧ください。
まずは、各種ライブラリをインポートし、画像データの前処理とDataLoaderを作成します。今回は問題を簡単にするために、RGBのカラー画像から白黒のみの画像に変換する処理を前処理に追加します。
それにより、入力データのチャンネル数は3から1になります。
import torch
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import random_split
import numpy as np
# データセットに対して行う前処理を定義
transform = transforms.Compose([
transforms.Grayscale(num_output_channels=1), # カラー画像をグレースケールに変換
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,)) # 1チャンネルなので、平均と標準偏差も1つずつに
])
# データセットのダウンロード
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
# トレーニングセットの全サイズを取得
total_size = len(trainset)
# トレーニングセットとバリデーションセットの割合を定義(例:トレーニング80%、バリデーション20%)
train_size = int(total_size * 0.8)
val_size = total_size - train_size
# トレーニングセットとバリデーションセットに分割
train_dataset, val_dataset = random_split(trainset, [train_size, val_size])
# トレーニングセットとバリデーションセット用のDataLoaderを作成
trainloader = torch.utils.data.DataLoader(train_dataset, batch_size=128, shuffle=True, num_workers=0)
valloader = torch.utils.data.DataLoader(val_dataset, batch_size=128, shuffle=False, num_workers=0)モデルの構築
次にモデルの構築を行いましょう。今回のモデルは画像のピクセルデータを入力値として受け取り、最終的には猫である確率を出力するので、最後の活性化層ではSigmoid関数を使えば良いということが分かります。以下のようなモデルを構築します。
入力データ(画像ピクセル) -> 全結合層 -> ReLU -> 全結合層 -> Sigmoid関数 (出力)
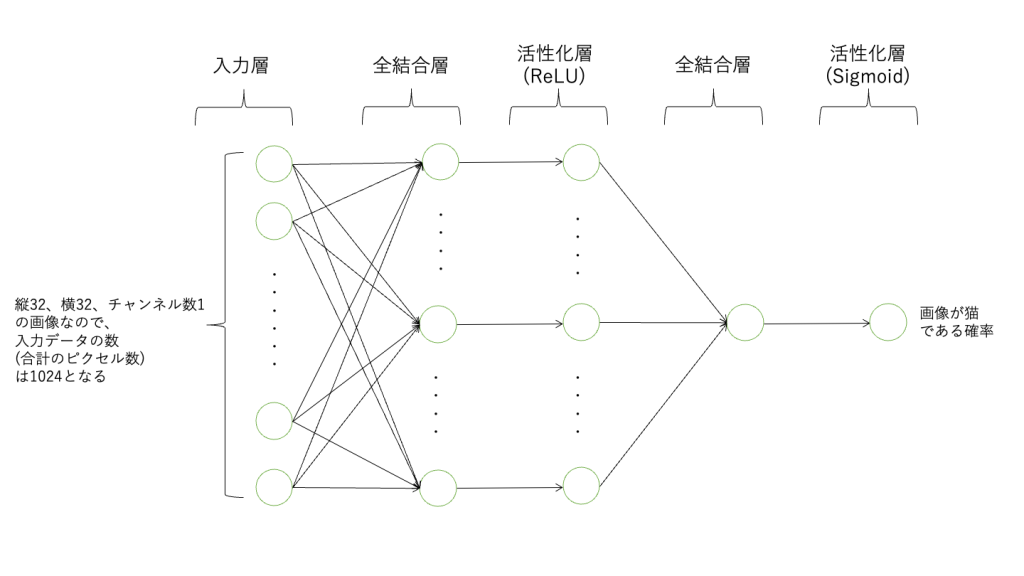
それではこのモデルをPytorchで構築してみましょう。まずコードの全体を以下に示します。
import torch.nn as nn
import torch.nn.functional as F
class CatClassifier(nn.Module):
def __init__(self):
super(CatClassifier, self).__init__()
# 入力画像はグレースケールで32x32のサイズ
# ここでは2つの全結合層を使用
self.fc1 = nn.Linear(32 * 32, 128) # 入力層から中間層へ
self.fc2 = nn.Linear(128, 1) # 中間層から出力層へ
def forward(self, x):
# フラット化(ピクセルデータを1次元に変換)
x = x.view(-1, 32 * 32)
# ReLU活性化関数を中間層に適用
x = F.relu(self.fc1(x))
# シグモイド関数を出力層に適用
x = torch.sigmoid(self.fc2(x))
return x
# モデルのインスタンスを生成
model = CatClassifier()- class CatClassifier(nn.Module)
CatClassifier は nn.Module を継承しています。PyTorchでは、自作でニューラルネットワークモデルを作成する際に(一般的に) nn.Module クラスを継承します。
- def __init__(self):
__init__ メソッドは、モデルの構造(レイヤー)を定義します。nn.Linearは全結合層で、第一引数に入力数、第二引数に出力数を指定します。self.fc1 は、32×32ピクセルの画像1024個の入力(32 * 32 = 1024)を受け取り、128個の出力を生成する一つ目の全結合層です。self.fc2 は、二つ目の全結合層で、fc1 層の出力と同数の128個を入力として受け取り、1個の出力を生成します。__init__ メソッドでは活性化層の定義は一般的に行いません。全結合層には重みやバイアスをいったパラメータがありますが、ReLUやSigmoidは単なる関数なのでパラメータはありません。__init__ メソッドでパラメータを持つモジュールを定義すると、PyTorchは自動的にこれらのパラメータを追跡し、最適化プロセス中に更新します。
- def forward(self, x):
forward メソッドは、入力データ x がネットワークを通過する際の流れ(順伝播)を定義します。
最初に入力データは、x.view(-1, 32 * 32)により1次元にフラット化します。画像データは(バッチサイズ, 32, 32, 1)の4次元構造となっており、全結合層に入力するため(バッチサイズ, 1024)の構造にする必要があります。-1を指定することで、PyTorchが32 * 32の計算結果からバッチサイズに自動的に調整します。
※バッチサイズとは
モデルは一般的にはデータを一つずつ学習するのではなく、ある程度まとめた数を一まとめにして学習を行います。この一部のデータを「ミニバッチ」といい、ミニバッチに使われるデータの数を「バッチサイズ」と呼びます。
今回はDataLoader作成時にbatch_size=32と指定したのでバッチサイズは32となり、、各ステップで32個のデータサンプルがモデルに供給されて学習が行われます。
バッチサイズを大きくすると、ミニバッチ内に含まれるデータの多様性が増すため、学習が安定するが学習速度が遅くなる傾向になります。また、バッチサイズを大きくし過ぎるとメモリ容量が不足する可能性もあるので、バッチサイズは総合的に考慮して決める必要があります。
損失関数の定義
今回のモデルは、猫の画像であるかどうかを二値(出力が0または1)で判断するバイナリ分類問題です。このため、バイナリクロスエントロピー損失(Binary Cross-Entropy Loss)が適切です。以下のように損失関数を定義します。
# 損失関数の定義
criterion = nn.BCELoss()- バイナリクロスエントロピー損失の役割
この損失関数は、モデルが出力する確率(猫である確率など)と実際のラベル(実際に猫かどうか)との違いを計算します。モデルの予測が正確(ラベルが1で出力の確率が1に近い)であれば、損失は小さくなります。逆に、予測が実際のラベルと大きく異なる場合、損失は大きくなります。
- 損失関数の数学的定義
バイナリクロスエントロピー損失関数の数式は以下の通りです。ここで、y は実際のラベル、y^ はモデルの予測値(0から1の間の確率)を意味します。
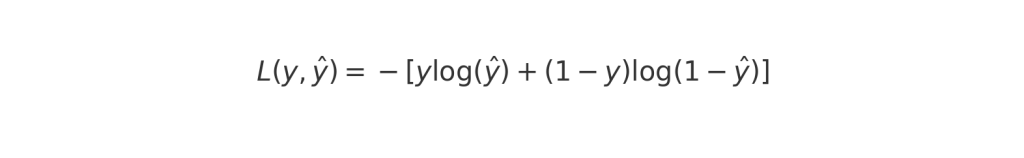
- 損失関数の働き
実際のラベルが1(猫)の場合、(1-y)は0となるので、式は-log(y^)になり、モデルの結果が正解の1であれば-log(1)で損失は0に、1から離れるほど損失は大きくなります。
対して実際のラベルが0(猫ではない)の場合、yは0となるので、式は-log(1-y^)になり、モデルの結果が正解の0であれば-log(1)で損失は0に、0から離れるほど損失は大きくなります。
最適化手法(Optimizer)の定義
続いてOptimizerの設定を行います。最適化手法(Optimizer)は、ニューラルネットワークの学習過程において、損失関数の値を減らす方向にモデルのパラメータ(重みとバイアス)を更新するためのアルゴリズムです。
損失関数の値が減るということは、モデルが正しく出力するようになるといえるので、モデルがトレーニングデータから学習して、より正確な予測を行えるようにするためアルゴリズムです。
- なぜ最適化手法が必要か
モデルがデータに対して予測を行うとき、最初はランダムなパラメータを使用します。これにより、初期の予測は不正確です。
損失関数はこれらの予測と実際のデータとの間の誤差を計算し、誤差逆伝播法は各パラメータと損失の関係(勾配)を明らかにします。その上で最適化関数はそれぞれのパラメータをどの程度変更するのかを決定するのです。
その結果モデルは徐々に改善され、データのパターンを学習します。
- 最適化手法の定義
今回は一般的によく使われるAdamという最適化手法を使います。
import torch.optim as optim
# 最適化手法の定義
optimizer = optim.Adam(model.parameters(), lr=0.0001)Adamの第一引数は更新対象とするパラメータを指定します。今回は全てのモデルの全てのパラメータを指定したいので、model.parameters()とします。
引数の「lr」は学習率です。学習率は、パラメータをどれだけ大きく更新するかを決定する値です。
学習率が高いとパラメータの更新が大きくなり学習が早くなりますが、安定して損失関数の最小値に収束せずモデルの性能が低下する可能性があります。
学習率が低いとパラメータの更新が小さくなり学習が遅くなります。また、局所的な最適解に収束してしまうリスクがあり、最適な解に到達しないことがあります。
モデルの学習
いよいよモデルの学習です。学習プロセスでは、定義したモデルに対してデータセットを使って順伝播と逆伝播を行い、パラメータを更新します。
一通りデータ全てに対して実行したら終了ではなく、パラメータは徐々にしか更新されないため何度も繰り返し学習する必要があります。その繰り返しの数をエポック数といいます。
モデル学習の流れを振り返っておきましょう。
- 順伝播: DataLoaderからバッチを取得し、モデルに入力して出力を得ます。
- 損失計算: 出力と実際のラベルとの間の損失を計算します。
- 逆伝播: 損失に基づいてモデルのパラメータの勾配を計算します。
- パラメータ更新: 最適化手法を使用してパラメータを更新します。
# エポック数の設定
epochs = 3
for epoch in range(epochs):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# バッチデータの取得
inputs, labels = data
# ラベルデータの変換
labels = (labels == 3).type(torch.float)
labels = labels.view(-1, 1).float()
# 勾配情報をリセット
optimizer.zero_grad()
# 順伝播
outputs = model(inputs)
# 損失計算
loss = criterion(outputs, labels)
# 逆伝播で勾配計算
loss.backward()
# パラメータの更新
optimizer.step()
# 損失の記録
running_loss += loss.item()
if i % 20 == 19: # 20ミニバッチ毎に出力
print(f'[{epoch + 1}, {i + 1:5d}] loss: {running_loss / 20:.3f}')
running_loss = 0.0何点かコードの説明を補足しましょう。
- ラベルデータの変換
まずラベルを猫をTrueにそれ以外をFalseに変換します。次に、labels.view(-1, 1).float()で (バッチサイズ, 1) の形式にした上で数値型に変換します。
(バッチサイズ, 1) の形式にした理由は損失計算のためにモデルの出力の構成と合わせるためです。
モデルは入力として (128, 32*32) を受け取り -> 全結合層1 (128, 128) -> 全結合層2 (128,1) と経て最終的に出力は (128, 1) の構成になります。その構成にラベルを合わせています。
- 勾配リセット
PyTorchでは、.backward()で勾配が計算されるたびに、勾配情報が蓄積されていきます。過去の勾配情報が残ったままだと、新たに更新したパラメータで勾配を計算した際に過去のものに加算されてしまい正常にパラメータの更新が行えません。
よって、optimizer.zero_grad()で毎回勾配情報をリセットする必要があります。
- 損失の記録
このコードは500ミニバッチごとに損失の平均値をprint文で出力しています。loss.item()で現在のミニバッチの損失を取得し、running_lossに加算していきます。そして定期的にprint文で損失を表示させ、学習がうまく進んでいるか確認することができます。
モデルの検証
モデルの学習の際に損失を表示し学習の進行を確認しましたが、モデルの性能を評価するには検証データを用いて行わなければなりません。そこで、検証データセット (valloader) を使用してモデルのパフォーマンスを評価します。
以下はモデルの学習に続いて検証を行うコードの例です。
for epoch in range(epochs):
model.train() # モデルをトレーニングモードに設定
# モデルの学習部分のコード (省略)
# 検証フェーズ
model.eval() # モデルを評価モードに設定
val_loss = 0.0
with torch.no_grad(): # 勾配計算を無効化
# 損失の合計を計算する
for inputs, labels in valloader:
labels = (labels == 3).type(torch.float)
labels = labels.view(-1, 1).float()
outputs = model(inputs)
loss = criterion(outputs, labels)
val_loss += loss.item()
average_val_loss = val_loss / len(valloader) # ミニバッチあたりの損失を計算
print(f'Epoch {epoch + 1} validation loss: {average_val_loss:.3f}') # 検証データの損失を表示- モデルのモード切り替え
model.train()はモデルを学習モードに切り替え、model.eval()は評価モードに切り替えます。このようにモードの切り替えを行う理由は、学習時と評価 (検証) 時で動作が異なる層があり、それに対応するためです。
今回の全結合層と活性化層はモードにより動作が異なるわけではないので、必ずしもモードの変更は必要ありません。しかし今後のために、学習時にはmodel.train()で学習モードにし、検証時にはmodel.eval() で評価モードにするようにしましょう。
- torch.no_grad()
PyTorchではloss.backward()で勾配を計算するために、順伝播[model(inputs)]の際に必要な情報を蓄積しています。しかし、検証フェーズではパラメータの更新は行わないので勾配の計算は不要です。
そこで、torch.no_grad()で順伝播の際の情報の蓄積を蓄積をやめることで、メモリを節約しつつ処理速度を上げることができます。
モデルの推論の実行
学習を行ったモデルを用いて実際に画像データを入力して猫の画像の確率を出力することができます。このように訓練されたモデルを使用して新しい未知のデータに対する予測や分類を行うことをモデルの推論といいます。
それではモデルの推論を行うコードを以下に示します。出力の確率が0.5を超えていたら猫の画像とモデルは予測したと判断します。
# モデルを評価モードに設定
model.eval()
# 推論用に検証データセットから一つのバッチを取得
dataiter = iter(valloader)
images, labels = next(dataiter)
# ラベルデータの変換
labels = (labels == 3).type(torch.float)
labels = labels.view(-1, 1).float()
# 勾配計算を無効化
with torch.no_grad():
# モデルにデータを通して予測を実行
outputs = model(images)
# 出力の確率を0,1に変換
predicted = (outputs > 0.5).float()
# 正解数を計算
correct = (predicted == labels).sum().item()
total = labels.size(0)
# 正解率の計算と表示
accuracy = 100 * correct / total
print(f'Accuracy: {accuracy:.2f}%')
コードの全体像
import torch
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import random_split
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# データセットに対して行う前処理を定義
transform = transforms.Compose([
transforms.Grayscale(num_output_channels=1), # カラー画像をグレースケールに変換
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,)) # 1チャンネルなので、平均と標準偏差も1つずつに
])
# データセットのダウンロード
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
# トレーニングセットの全サイズを取得
total_size = len(trainset)
# トレーニングセットとバリデーションセットの割合を定義(例:トレーニング80%、バリデーション20%)
train_size = int(total_size * 0.8)
val_size = total_size - train_size
# トレーニングセットとバリデーションセットに分割
train_dataset, val_dataset = random_split(trainset, [train_size, val_size])
# トレーニングセットとバリデーションセット用のDataLoaderを作成
trainloader = torch.utils.data.DataLoader(train_dataset, batch_size=128, shuffle=True, num_workers=0)
valloader = torch.utils.data.DataLoader(val_dataset, batch_size=128, shuffle=False, num_workers=0)
class CatClassifier(nn.Module):
def __init__(self):
super(CatClassifier, self).__init__()
# 入力画像はグレースケールで32x32のサイズ
# ここでは2つの全結合層を使用
self.fc1 = nn.Linear(32 * 32, 128) # 入力層から中間層へ
self.fc2 = nn.Linear(128, 1) # 中間層から出力層へ
def forward(self, x):
# フラット化(ピクセルデータを1次元に変換)
x = x.view(-1, 32 * 32)
# ReLU活性化関数を中間層に適用
x = F.relu(self.fc1(x))
# シグモイド関数を出力層に適用
x = torch.sigmoid(self.fc2(x))
return x
# モデルのインスタンスを生成
model = CatClassifier()
# 損失関数の定義
criterion = nn.BCELoss()
# 最適化手法の定義
optimizer = optim.Adam(model.parameters(), lr=0.0001)
# エポック数の設定
epochs = 3
for epoch in range(epochs):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# バッチデータの取得
inputs, labels = data
# ラベルデータの変換
labels = (labels == 3).type(torch.float)
labels = labels.view(-1, 1).float()
# 勾配情報をリセット
optimizer.zero_grad()
# 順伝播
outputs = model(inputs)
# 損失計算
loss = criterion(outputs, labels)
# 逆伝播で勾配計算
loss.backward()
# パラメータの更新
optimizer.step()
# 損失の記録
running_loss += loss.item()
if i % 20 == 19: # 20ミニバッチ毎に出力
print(f'[{epoch + 1}, {i + 1:5d}] loss: {running_loss / 20:.3f}')
running_loss = 0.0
for epoch in range(epochs):
model.train() # モデルをトレーニングモードに設定
# モデルの学習部分のコード (省略)
# 検証フェーズ
model.eval() # モデルを評価モードに設定
val_loss = 0.0
with torch.no_grad(): # 勾配計算を無効化
# 損失の合計を計算する
for inputs, labels in valloader:
labels = (labels == 3).type(torch.float)
labels = labels.view(-1, 1).float()
outputs = model(inputs)
loss = criterion(outputs, labels)
val_loss += loss.item()
average_val_loss = val_loss / len(valloader) # ミニバッチあたりの損失を計算
print(f'Epoch {epoch + 1} validation loss: {average_val_loss:.3f}') # 検証データの損失を表示
# モデルを評価モードに設定
model.eval()
# 推論用に検証データセットから一つのバッチを取得
dataiter = iter(valloader)
images, labels = next(dataiter)
# ラベルデータの変換
labels = (labels == 3).type(torch.float)
labels = labels.view(-1, 1).float()
# 勾配計算を無効化
with torch.no_grad():
# モデルにデータを通して予測を実行
outputs = model(images)
# 出力の確率を0,1に変換
predicted = (outputs > 0.5).float()
# 正解数を計算
correct = (predicted == labels).sum().item()
total = labels.size(0)
# 正解率の計算と表示
accuracy = 100 * correct / total
print(f'Accuracy: {accuracy:.2f}%')以上がモデルを学習し、推論に利用するまでの流れとなります。ここまで理解できればディープラーニングの基礎を理解できたと言っても良いでしょう。分からない箇所があれば過去の記事なども参照しながら理解を深めていきましょう。
